Stardog needs a new low-level storage engine. You won’t believe what happened next.
Background
Stardog has a storage engine much like other persistent databases. It has its quirks but has served us pretty well. But “pretty well” isn’t good enough, and our storage engine dates to the earliest days of Stardog development anyway, so we’ve been taking a long hard look to see if we can improve it. We identified a few issues that merit a rework, which is what I’m working on these days.

Courtesy of Michael (a.k.a. moik) McCullough
But swapping a storage engine isn’t like changing the oil in a car. It’s a complex, central component of the system. Changes made to the storage engine will have reverberations throughout all of Stardog—from query and update performance to transactions and concurrency. It even affects how we model our clustered environment.
So it makes sense to consider carefully what our current engine is, what we think is good and bad about it, and why we decided that we needed to undertake such a project.
The Status Quo: Copy on Write B-Tree
We will simplify a lot of details and just say that Stardog’s current storage model is a Copy-on-write B-Tree. B-Trees are famous. They’ve been around since the ‘70s, mainly because they work pretty well. They provide very good read performance, decent write performance, and relatively easy configuration.
The thing about B-Trees is that transactional concurrency is tricky. You have to write locks for rows, pages, tables, and a half-dozen other units. These locks can deadlock so you have to maintain some kind of deadlock detection. Each lock has to be tested. The locks can interact in unusual ways. Lock-based concurrency on a B-Tree is hard. A much simpler model is to use “copy-on-write” (COW) semantics.
In COW each write will make a copy of the tree, then modify that copy directly—though to be fair, we only make physical copies of the affected pages. Then when the transaction is ready to commit, we swap out the original tree and replace it with the copy. Any read while we are writing just looks at the original copy.

Courtesy of Ken Bosma
COW B-Trees have the same read performance as classic B-Trees, but much better read concurrency because there are neither locks nor any other mechanisms to block readers at any point during a read. However, they pay a significant price in both write performance and write concurrency. Because we make copies of entire pages during the write phase, we are actually performing more physical writing than in a traditional B-Tree.
What’s worse, COW semantics can lead to conflicts between multiple writers. For example, if writer A and B attempt to perform a write simultaneously, we have the following sequence:
- A gets initial tree information (tree in State 0)
- B gets initial tree information (tree in State 0)
- A makes changes, creating State 1
- B makes changes, creating State 2
- A attempts commit, moving shared tree from State 0 to 1
- B attempts commit, moving shared tree from State 1 to 2
In this sequence of events, A’s writes are lost, which is obviously a bad thing for A.
the state of conflict
This is a classic example of a write-write conflict, but COW semantics don’t give us any clue what to do here. We can allow A to succeed, but somehow perform a detection on B to indicate that the state has changed out from under it. Or we can only allow a single writer at a time.
Allowing a single writer to manipulate the tree simultaneously is easy, but results in very poor write concurrency. On the other hand, if we try to allow A but fail B, then B would need to retry her writes against A’s state. This would result in B doing the same work multiple times, with no guarantee of success at any point—after all, a new writer could come in and do more writes before B can finish her work. In the end, it’s functionally the same as single writer.
The main strength of COW B-Trees is the scenario where you load some data, then do a bunch of different queries on it. As long as that’s your model, the current engine works quite well. In this situation you have many read transactions, but maybe only one or two writers that are writing relatively large volumes of data at long intervals. But this scenario isn’t the only way in which people want to use Stardog, so we need to improve performance for other workloads, too.
The Alternatives
So COW B-Trees aren’t the answer. What are the alternatives?
Classic B-Tree
We could move to a classic B-Tree, of course. Just dump the COW.

Courtesy of David DeHetre
But that would require entering into the complicated world of locking structures. Zero fun for us and not much better for you. At best we’d end up with a data structure that doesn’t perform all that well on write workloads.
This isn’t a huge deal for our RDBMS friends because they really don’t write data into too many locations. Most RDBMS recommend using only one or two indices for each table. Precisely to avoid crappy write performance. Alas, Stardog maintains 15 separate disk-based indices for query evaluation. Even if that number shrank to 5 or 6, B-Trees are probably not the correct data structure for us.
LSM Tree
An alternative approach is that of a Log-Structured Merge Tree (or LSM Tree). LSM Trees have gotten popular lately, mainly due to the success of Cassandra, HBase, and LevelDB, each of which attempted to solve the problem of write-performance and concurrency issues in B-Trees themselves.
I think that I shall never see…
An LSM tree is made up of three parts: a write-ahead-log, a set of sorted files, and a sorted in-memory representation. Writes go first to the write-ahead-log (WAL), then to an in-memory sorted structure (the memstore). When the memstore reaches a configured limit, it is flushed to disk, creating a single file (called an sstable), which is sorted in the same order as the memstore. Reads are basically the inverse. Read from each sstable and the memstore, then merge the results together to form a single sorted representation of the data.
Thus the write-performance problem and the write-concurrency problem is solved in a single swipe. Write performance is very fast because the only I/O required is a single entry in the WAL. Because WAL entries are ordered only by the time which the write was submitted, the concurrency on a write is only bounded by the hardware on the machine it’s running on.
However, it is done at a significant cost to read performance. Over time, as more and more writes are made against the system, more and more files are created which will need to be accessed in order to perform a read. The cost of merging all these files together poses an unacceptable burden on read speed.
In response, LSM trees usually include a compaction system, which selects a subset of all written sstables and merges them into a single sstable containing all the data pre-merged. This keeps the number of files in an index to a reasonable number and helps keep read performance within acceptable bounds.
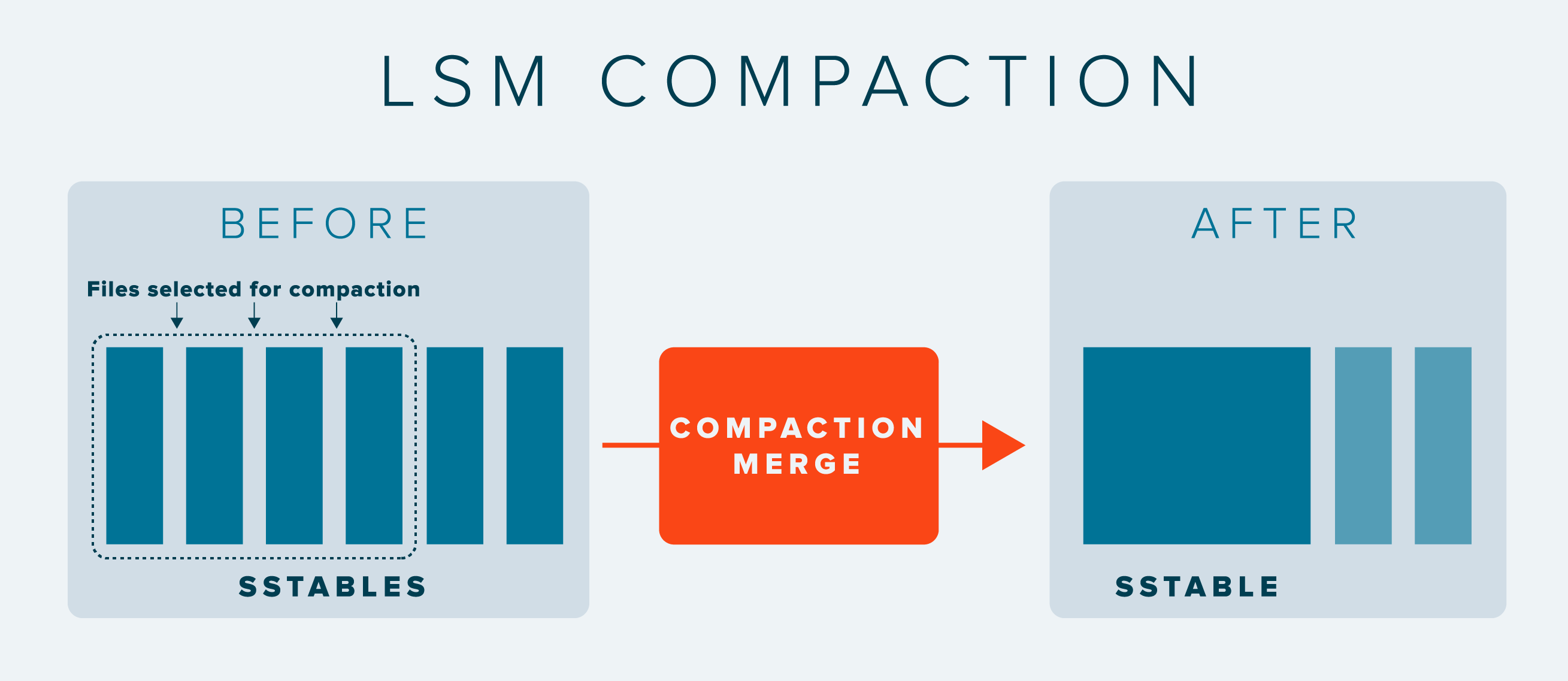
Alas it also tends to cause a lot of disk I/O to happen in a big burst, which can negatively affect both read and write performance during compactions. As a result, tuning compaction frequency and compaction strategies tends to occupy a not-insignificant portion of an administrator’s time.
…a data structure lovely as an LSM Tree
Notwithstanding compactions, we can maintain good write performance and concurrency while holding steady on read performance. But what about read concurrency? As it turns out we won’t pay too much for it. There is some coordination overhead in reading data from the memstore, but high-concurrency data structures—think: Skip lists—help offset. Reading the sstables requires no synchronization at all because sstables are immutable–they are never modified in place, only copied to new sstables during compactions.
LSM trees have much better write performance and write concurrency, while paying a modest price in read performance and no penalty at all in read concurrency. LSM trees are a much better solution to Stardog’s storage problems than B-Trees.
But nothing is easy. Easy shipped and got acquired years ago. The move from COW B-Tree to LSM tree is difficult. COW B-trees manage transactional state as part of the data structure itself, rather than as a function of the data contained in the structure. By contrast LSM trees provide no global concurrency control mechanisms with which to accomplish the same task. Instead we have to devise our own transactional support for LSM trees.

Courtesy of Claudio Gennari
We could fall back on the lock happy thing: row lock, region lock, table lock, where does it end? But that would suck for read and write concurrency, but at least it’s complicated and prone to deadlock. Instead, we use multiversion concurrency control, storing transactional information along with the data itself inside the index. This uses more disk space but allows us to construct a simple transactional model with the same guarantees that our current structure does, without requiring us to fidget with locks for the next 10 years.
Conclusion
Stardog is going LSM Tree and MVCC. Fun stuff. Stay tuned for more details about Stardog’s new storage engine—codenamed Mastiff—and some of the implementation challenges we’ve already solved and which ones remain.
Download Stardog today to start your free 30-day evaluation.
Scott Fines
2 May 2017
![]()
![]()
![]()
