We’re adding graph traversal to Stardog to support a broader range of graph queries and analysis. Now that we’ve figured out how to extend SPARQL solutions, we can more easily make Stardog traverse graphs to find paths and other relationships.
Download Stardog today to start your free 30-day evaluation.
Background
SPARQL is a powerful graph query standard for RDF that provides a SQL-like syntax that allows querying graph patterns along with many other features like optional patterns, unions, subqueries, aggregation, and negation. As we briefly discussed in a previous post, there is one notable limitation with SPARQL: finding paths between nodes is not easy. Path finding is not easily achievable in SPARQL mainly because a path of edges cannot be naturally represented in the tabular result format of SPARQL.
SPARQL has a property path feature that can be used for queries that recursively traverse the RDF graph and find two nodes connected via a complex path of edges. But the result of a property path query is only the start and end nodes of the path and does not include the intermediate nodes. To find the intermediate nodes additional or more complex queries are needed.

Simon Matzinger
Finding Our Path
So we are extending Stardog so that users can easily express a path finding query inside SPARQL, which will allow finding and retrieving paths of arbitrary complexity. We’ve code named this extension Pathfinder.
The goal of Pathfinder is an elegant, concise syntax for path queries in SPARQL—and, of course, a performant, scalable implementation, too. There are several kinds of path finding problems to address. We want to find paths between a fixed pair of nodes or between all nodes. We want to find any path versus only shortest paths, possibly based on a weight. And sometimes there might not be an explicit edge between two nodes, but there might be a graph pattern corresponding to a relationship that links these nodes. It should be possible to find paths over these implied relationship edges, too.
We will publish more details about the syntax and the semantics of this extension later, but in this post we will simply describe how path queries will work using some examples. First, let’s look at the syntax of path queries:
PATH ?p FROM ([startNode AS] ?s) TO ([endNode AS] ?e) {
GRAPH PATTERN
}
[ORDER BY condition]
[LIMIT int]
Suppose we have this very simple social network where people are connected via knows relationship:
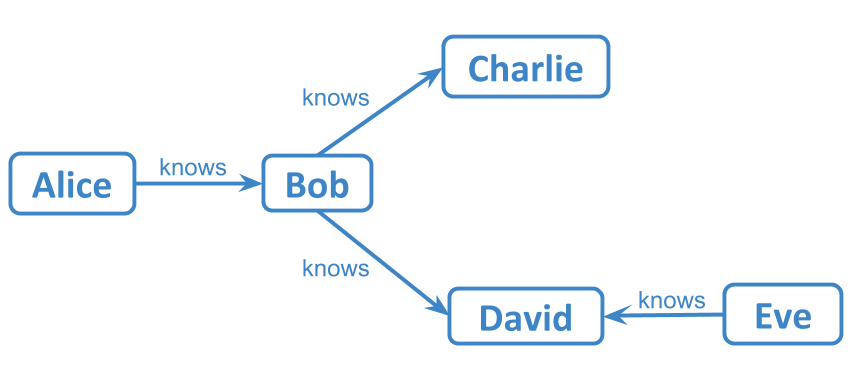
Now suppose we want to find all the people Alice is connected to and how she is connected to them. The corresponding path query looks like this:
PATH ?p FROM (:Alice AS ?x) TO ?y {
?x :knows ?y
}
We specified a start node for the path query, but the end node is unrestricted. So all the paths starting from Alice will be returned. This query is effectively equivalent to the SPARQL property path :Alice :knows+ ?y, but the results will include the nodes in the path(s).
The results of a path query is a list of solutions, but we use the extended solutions introduced previously. The result of the above query would look like this:
[
{"x": ":Alice", "y": ":Bob", "p": [ {"x": ":Alice", "y": ":Bob"} ] },
{"x": ":Alice", "y": ":Charlie",
"p": [ {"x": ":Alice", "y": ":Bob"}, {"x": ":Bob", "y": ":Charlie"} ] },
{"x": ":Alice", "y": ":David",
"p": [ {"x": ":Alice", "y": ":Bob"}, {"x": ":Bob", "y": ":David"} ] }
]
There is one solution for each path found. In each solution the start and end variables are bound to the start and end nodes of the path respectively. The path variable ?p is bound to one and only one array of edges. Each edge is also a solution that binds the variables of the graph pattern.
Execution happens by recursively evaluating the graph pattern in the query and replacing the start variable with the binding of the end variable in the previous execution. If the query specifies a start node, that value is used for the first evaluation of the graph pattern. If the query specifies an end node, which our example doesn’t, execution stops when we reach the end node. Cycles are not allowed in the results.
Graph patterns inside the path queries can be arbitrarily complex. Suppose, we want to find undirected path between Alice and Eve in this graph. Then we can make the graph pattern to match both outgoing and incoming edges:
PATH ?p FROM (:Alice AS ?x) TO (:Eve AS ?y) {
?x :knows|^:knows ?y
}
This query would return:
[
{"x": ":Alice", "y": ":Eve",
"p": [ {"x": ":Alice", "y": ":Bob"},
{"x": ":Bob", "y": ":David"}, {"x": ":David", "y": ":Eve"} ] }
]
But these results don’t show the direction of the relationship at each step. We can instead use a UNION to query both directions and another variable to indicate direction:
PATH ?p FROM (:Alice AS ?x) TO (:Eve AS ?y) {
{ ?x :knows ?y BIND(true as ?forward) }
UNION
{ ?y :knows ?x BIND(false as ?forward) }
}
The results for the query is as follows:
[
{"x": ":Alice", "y": ":Eve",
"p": [ {"x": ":Alice", "y": ":Bob", "forward": true},
{"x": ":Bob", "y": ":David", "forward": true},
{"x": ":David", "y": ":Eve", "forward": false} ] }
]

Using graph patterns is necessary when there are no direct edges between the nodes. For example, consider the Six Degrees of Bacon game using the DBpedia dataset. There are no direct links between actors and actresses in the graph, but there are movies in which they acted together. The path query for finding the path between Keanu Reeves and Kevin Bacon would look like this:
PATH ?path FROM (dbr:Keanu_Reeves As ?start) TO (dbr:Kevin_Bacon AS ?end) {
?movie a dbo:Film ;
dbp:starring ?start ;
dbp:starring ?end .
}
The result for the query would look like this:
[
{"start": dbr:Keanu_Reeves, "end": "dbr:Kevin_Bacon",
"path": [ {"movie": "dbr:The_Matrix",
"start": "dbr:Keanu_Reeves", "end": "dbr:Laurence_Fishburne"},
{"movie": "dbr:Mystic_River_(film)",
"start": "dbr:Laurence_Fishburne", "end": "dbr:Kevin_Bacon"} ] }
]
Arbitrary graph patterns in path queries make this a general recursive graph traversal operator that can be used to extract arbitrary subgraphs.
https://xkcd.com/
Shortest Path to Happiness
If we are interested in finding only the shortest paths, then we need to add an ordering condition:
PATH ?path FROM (dbr:Keanu_Reeves As ?start) TO (dbr:Kevin_Bacon AS ?end) {
?movie a dbo:Film ;
dbp:starring ?start ;
dbp:starring ?end .
}
ORDER BY length(?path)
LIMIT 1
We are using ORDER BY length(?path) to return the shortest paths first and LIMIT 1 will cause the query to return a single path. Recall that the length function was defined as part of extended solutions) and returns the number of elements in an array which in this case is the number of edges in a path.
If there are multiple paths with the same length then an arbitrary one would be returned. The path query specification does not say anything about how the ordering functionality will be implemented, but Stardog will be taking these modifiers into account to use the most efficient path finding algorithm.
We can use a very similar query to compute the Erdös number of people using the DBLP Bibliography Database:
SELECT (length(?path) AS ?erdosNumber) ?path {
PATH ?path FROM (:Evren_Sirin AS ?start) TO (:Paul_Erdos AS ?end) {
?article a foaf:Document ;
dc:creator ?start ;
dc:creator ?end
}
ORDER BY length(?path)
LIMIT 1
}
This query highlights the fact that, just like other query types, we can use path queries as subqueries. In this example, we are using the outer SELECT expression to assign the length of the path to the erdosNumber variable. Path queries will follow the general bottom-up evaluation semantics of SPARQL. Variables used in the graph patterns will not be visible from the outside.
Shortest path problems sometimes involve assigning a weight to each edge and finding the path with lowest total weight. For example, the following query is for finding the shortest route between two cities based on distance:
PATH ?p FROM ?city1 TO ?city2 {
?r a :Road ;
:startsAt ?city1 ;
:endsAt ?city2 ;
:distanceInMiles ?distance
}
ORDER BY sum(project(?p, ?distance))
LIMIT 1
The order condition first uses the project function which takes as input an array of solutions and then projects the bindings of a given variable as an array. Then we apply the sum aggregation function to the array of values to compute the total distance.

There are many other possibilities with path queries. We will mention a few more examples briefly to show different uses of path queries.
Let’s find cyclic dependencies in a graph:
SELECT ?cycle {
PATH ?cycle FROM ?start TO ?end {
?start :dependsOn ?end
}
FILTER (?start = ?end)
}
This query is not very verbose but still looks more complex than the SPARQL query ?x :dependsOn+ ?x which would detect cyclic dependencies. But the SPARQL query does not return the nodes involved in the cycle. One possibility we are considering is a shorthand version of path queries when the graph pattern is a single triple pattern, e.g. path ?p { ?x :dependsOn ?x }.
Or we retrieve the Concise-bounded description (CBD) of a specific node (i.e., resource):
CONSTRUCT { ?s ?p ?o }
WHERE {
PATH ?path FROM (:resource AS ?s) TO ?o {
?s ?p ?o
FILTER (isBlank(?s) || ?s = :resource)
}
}
Summary
We are actively working on the Pathfinder extension and will release it in Stardog later this year. Let us know if you have any feedback for this extension.
Download Stardog today to start your free 30-day evaluation.
Evren Sirin
14 March 2017
![]()
![]()
![]()
