We’re prepping Stardog 5 beta for release. If data siloes rule everything around you, then you need to build a Knowledge Graph with Stardog 5.
TLDR: We’ve made Stardog easier, faster, more resilient, and more useful.

1. AWS Deployments are Trivial
Let’s start with push-button AWS deployments, i.e., the stuff that gets you home from work on time. It’s now dead simple easy to deploy Stardog.
Stardog Graviton—our first Apache-licensed, Golang project—compiles to a single binary executable that lives on a client machine and provides a one-click virtual appliance installation of Stardog HA Cluster. It leverages the power of Amazon Web Services to deploy, configure, and launch all of the virtual hardware and software needed for an optimal Stardog cluster deployment. All you have to provide is the AWS account.
Now, as the man once said, watch this video!
Say thanks to John Bresnahan who wrote Graviton because he lives in Hawaii and ain’t nobody got time for manual deployments when they could be paddling!
2. Tableau for a Great Good
A knowledge graph relates data from anywhere, in any format, to data from everywhere else. Knowledge graph is to data as Cloud is to compute and SANs are to storage. And one of the uses for a knowledge graph is better understanding faster, including analytics and visualizations.
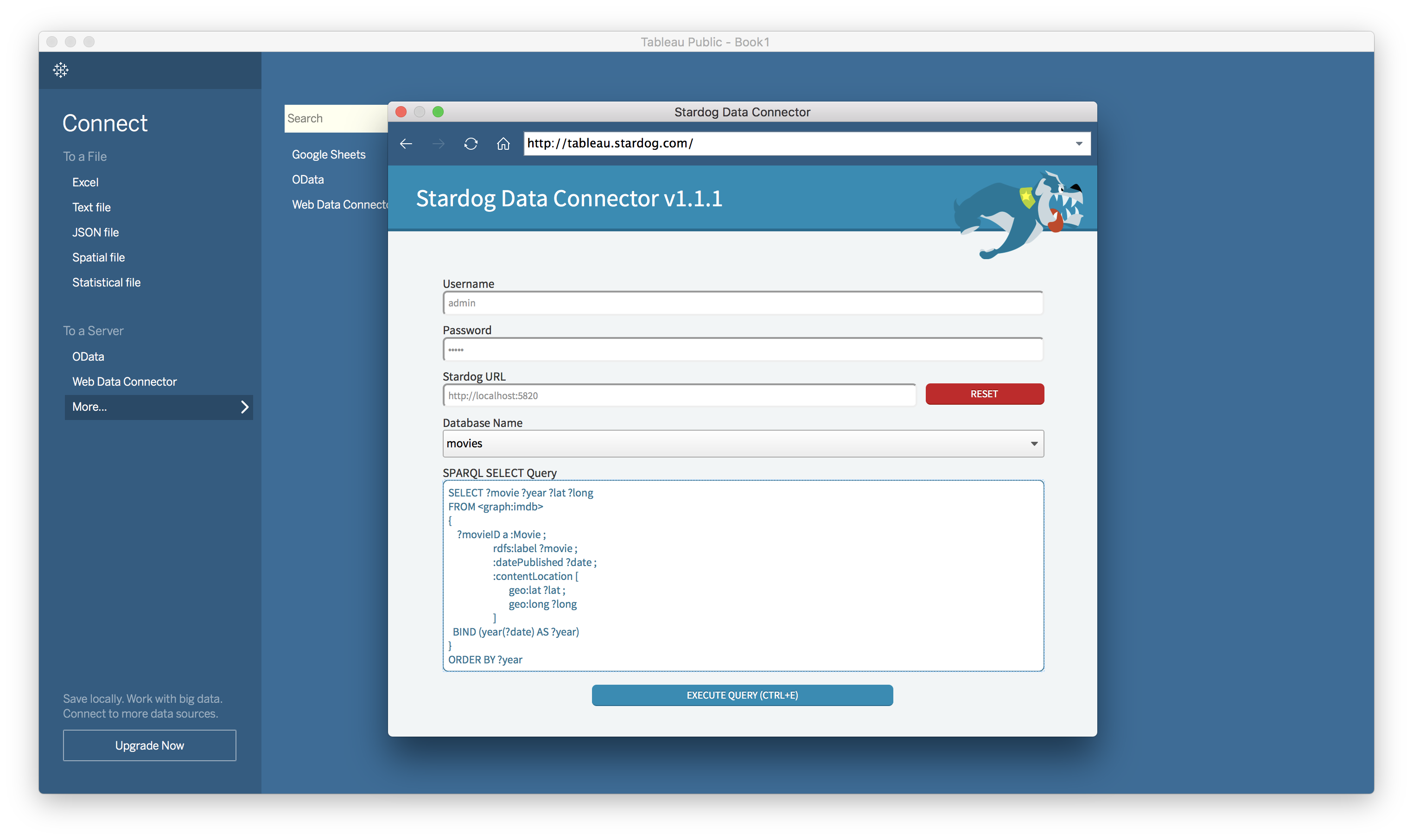
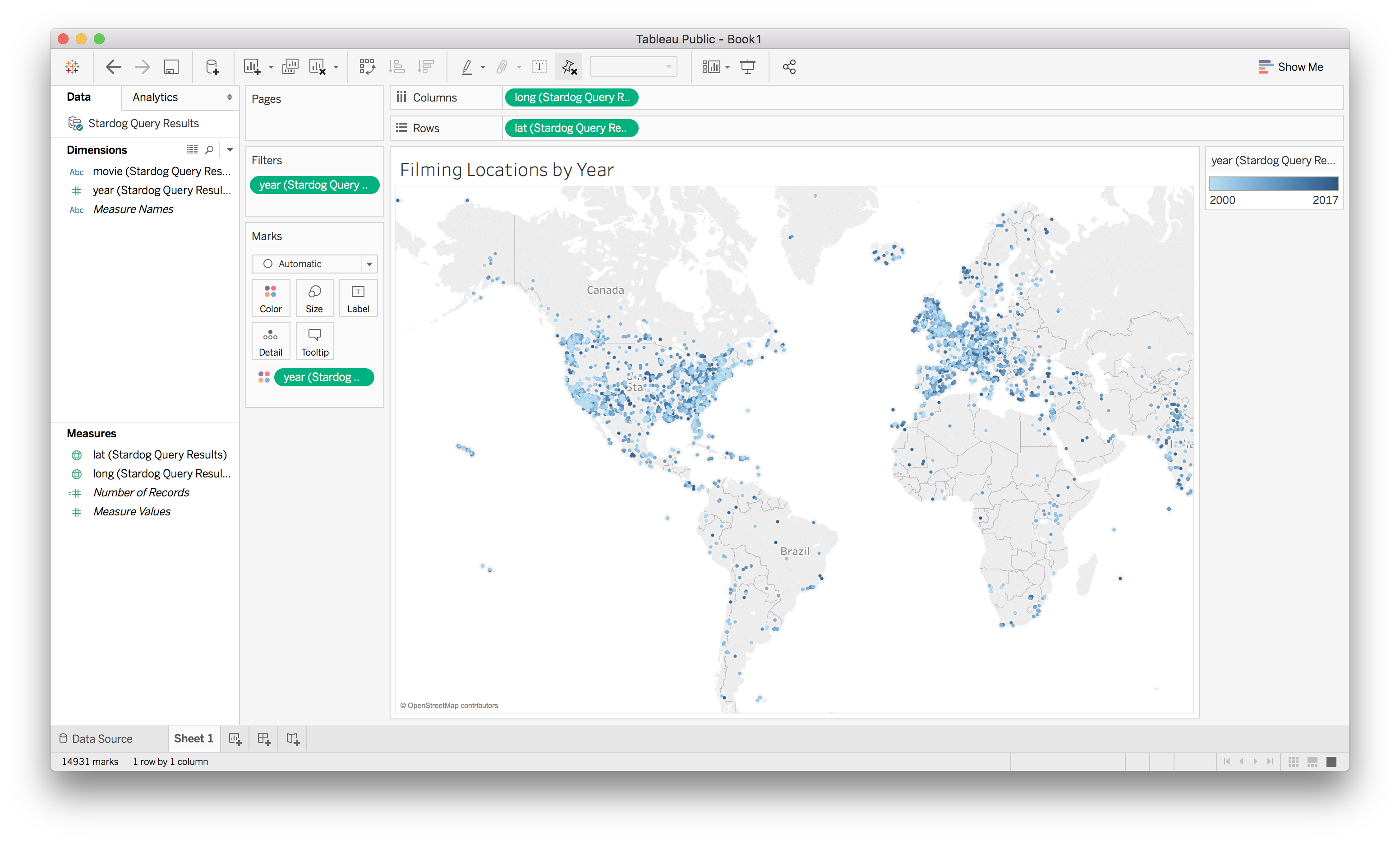
For Stardog 5 we’ve implemented Tableau support so that you can use Tableau’s visualization powers to take advantage of the knowledge graph.
You can get the Stardog Data Connector for Tableau here.
Thanks to the plucky Javascript-focused law firm of Bretz, Soehngen, & Ellis for this work.
3. Queries, Search, and Geospatial are Faster
More or less everything in Stardog 5 is faster, more scalable, and faster, but especially query, search, and geospatial.
New Statistics → Faster Queries
In the query eval game, lots of small changes can add up to non-trivial gains, but we also made some bigger changes, too. For example, statistics. Statistics are important for query costing and, hence, for query planning and optimization. But they can be prohibitively expensive to compute and are one of the dark
arts of database design and programming.
We not only wanted stats to be more accurate but we also wanted them to be cheaper, too. The count-min sketch turned out to be just the thing. Stardog 5 computes statistics in a single streaming pass through one index and doesn’t build any auxiliary persistent data structures. Stardog 5 stats include two probabilistic data structures to replace the previous persistent maps to store object counts for each characteristic set. First, we build a count-median-min sketch to answer frequency queries for objects. This one is compact and very accurate for frequently occurring objects. Second, we use a Bloom filter to answer membership queries for rarely occurring objects.
Bloom filters have linear space requirements which make them expensive to build and manage. Also their size is difficult to know ahead of time since we don’t know the size of each characteristic set before we build it. Therefore, we take a fixed-size uniform sample of objects occurring in each set using the reservoir sampling technique and build the Bloom filter accordingly.
For some graphs more accurate statistics make a huge difference in performance. For example, on Yago Stardog 5 is 1,600% faster than Stardog 4.

Pavel Klinov did this work, and he’s so modest that he basically forgot it, stashed in a branch for more time than any of us would like to admit. He’s also an avid cyclist and refuses any Stardog stickers on his new, hand-built frame because “excess weight kills”. At scale, in databases and bike races, everything matters.
Faster Search, Too
We improved performance for Stardog’s semantic search capability significantly by optimizing the way we use Lucene. We reduced search times in some hard cases from several seconds to milliseconds. And by “we”, I mean Pedro Oliveira.
The improvements involved using SearchManager more cleverly and deleting lots of unnecessary code. It also involved recognzing our interactions with Lucene are batch and transaction-oriented, in which case it made more sense to use a new IndexWriter with each transaction. They occupy a fair bit of memory and are only optimized on close().
- A union of 100
textMatch, Stardog 5 is 1,300% faster than Stardog 4 - A join of 30
textMatch, Stadog 5 is 416% faster than Stardog 4.
Geospatial is bigly faster…Not sad!
We also improved the performance of spatial queries significantly, largely by following some of the same tracks laid down in the base Lucene case. Some of these numbers are, frankly, a little hard to believe, but they’re real.
- Queries with
geo:nearby, from 13 seconds to 10 milliseconds - Queries for objects in vicinity of several locations, from 12 seconds to 21 milliseconds
- Queries with
geo:wktLiteral, from 10 seconds to 100 milliseconds - Queries for a point
geo:withina polygon, from 15 seconds to 2.5 seconds…a mere 600% increase, maybe a little sad?!
Some other geospatial performance improvements go beyond query answering:
- Bulk-loading of spatial data is about 80% faster
- Deletes that involve the search index are roughly 100% faster overall; when there are several named graphs, the improvement is even better—transactions that took minutes now take milliseconds
- Indexing of search data with named graphs is up to 300% faster
To be honest these search and geospatial numbers are sick, and I blame Pedro Oliveira for them 100%.
4. Query Hints are a Thing
Our query planner is state of the art for graph databases, but query hints are real and they can be fabulous. So we’ve added them to Stardog 5. We will add new hint types in the 5.x release cycle, including for (1) reasoning: define the reasoning mode for a scope; (2) virtual graphs: supply information on cardinality; (3) query eval: suggest specific join algorithms for scopes with two patterns; (3a) whether or not to reorder filters in a scope; (3b) whether or not to use parallel unions, etc.

Image courtesy of Duncan Hull
In this release we support two hints. First, assume.iri tells Stardog that the variables ?o and ?o2 will only be bound to a graph node (i.e, IRIs) and not to a node property (or its value).
select ?s where {
#pragma assume.iri ?o, ?o2
<ns:a> ?p ?o .
<ns:b> ?p2 ?o2
}
Second, the group.joins hint introduces an explicit scoping mechanism to help with join order optimization. Finding the optimal order of joins for an arbitrary set of triples patterns is no easy task, especially if the query contains many triple patterns. Stardog does a very good job most of the time. The new statistics really help.
But in cases where Stardog fails to find the optimal join order you can guide the optimizer to use a specific join order using a hint:
select ?s where {
?s1 :p ?o1 .
{ #pragma group.joins
#these patterns will be joined before being joined with anything else
?s1 :p ?o2 .
?o1 :p ?o3 .
}
}
Our hints are safely ignored as comments by other systems, but really why would you even think of doing that? Again, thanks to Pedro and Pavel for the query hints work. More of this to come throughout 5.x.
5. Garbage Collection (almost) Never Happens
Alexander Toktarev already blogged (“Saying Goodbye to Garbage”) about how memory management in Stardog 5 goes from the conventional Java garbage collection to some other completely different thing. No, no, go read that post. I’ll wait, it’s fascinating stuff. Alexander is, needless to say, a very serious JVM engineer.
Stardog 5 memory management uses some real cutting-edge JVM techniques—which you’ll also find in things like Apache Flink and the like—to allocate memory in collections using byte arrays in such a way that no JVM GC occurs. See Alex’s post for some of the details. Since that post we’ve been working on using Stardog 5 MM (“memory management”) in the mapping dictionary and in other places, too.
Saying goodbye to JVM GC in Stardog 5 means more predictability, more stability, better performance at scale, and no irritating stop-the-world pauses. Stardog 5 should never OOM and sees dramatic speedups on some very complex queries.

Image courtesy of jlwelsh
For example, an financial services customer has a very complex forensics query that Stardog 4 just couldn’t evaluate. Stardog 5 evaluates this query in about 2 minutes. In some limited cases we see a small slowdown by a constant factor, but we expect that to be negligible and rare by Stardog 5 final release.
6. Core Server is Better in Every Way
Stardog core server has always been a fairly complex pile of Netty code. Mike Grove wrote all of that code, more or less, so he knew how hard it was to reason about. Sometimes customers saw puzzling deadlocks that were hard to reproduce and even harder to fix.
So Mike decided to replace Netty with Undertow. A couple of benefits accrued to us almost immediately. First, Mike got to delete about 60,000 lines of code net. Be jealous. That doesn’t happen often. The new server is also simpler, easier to extend and reason about, as well as measurably faster.
The new server has a simplified threading model, which means that it’s easier to segment requests by type into separate thread pools and to partition reads and writes and control the resources they use. It also means that what thread or thread pool something runs in is much more obvious. The new server is also much less prone to thread starvation by overloading a pool or inadvertently blocking in an I/O thread.
The new server is easier to develop against for us internally and easier for everyone else to extend. The API is more concise, with a smaller, flatter learning curve. It also allows for greater reuse of services via composition. For example, our implementation of SPARQL Protocol is now 40% less code.
User-defined extensions of the new server are really easy. You just have to implement a single interface, declare it such that the JDK service loader picks it up, put it in the classpath, and restart the server. See the Stardog 5 docs for details.

All that and no performance penalty. In fact, we consistently measure 12% better throughput.
7. Virtual Graphs are Faster and Easier to Extend
We will publish a blog post from Jess Balint—who built the new Virtual Graph engine in Stardog 5—soon after the beta release. It will include lots of details. For now here’s a quick preview. Stardog 5’s Virtual Graph service is rewritten from scratch:
- new optimizations to minimize joins
- new optimizations for SPARQL
OPTIONAL - pushes aggregates and subqueries down to source systems
- heavy use of Apache Calcite
- create-time validation of mappings
- Apache Hive support
Jess previously wrote about Stardog’s Virtual Graph capability in Virtual Graphs: Relational Data in Stardog. Jess heavily recruited us before we closed our seed round last year and we’re very glad we said yes.
8. Cluster is More Resilient
We’ve completely reworked how HA Cluster works, including how it uses Zookeeper. This work was done by Evren Sirin, Paul Marshall, Mike Grove, John Bresnahan, and Scott Fines. As Paul Marshall blogged (in “Blockading Stardog”), we’ve added a new kind of testing to Stardog Cluster (“controlled chaos”) using the Blockade open source tool. This means adding extensive test suite, torture testing, chaos testing to the rest of our testing regime.
Test coverage for the Cluster has increased dramatically. We also improved Cluster sync performance at new node join time, which helps Stardog customers in production.
Improved Performance
Data loading performance in the Cluster, which is critical to uninterrupted operations, has also dramatically improved in Stardog 5.
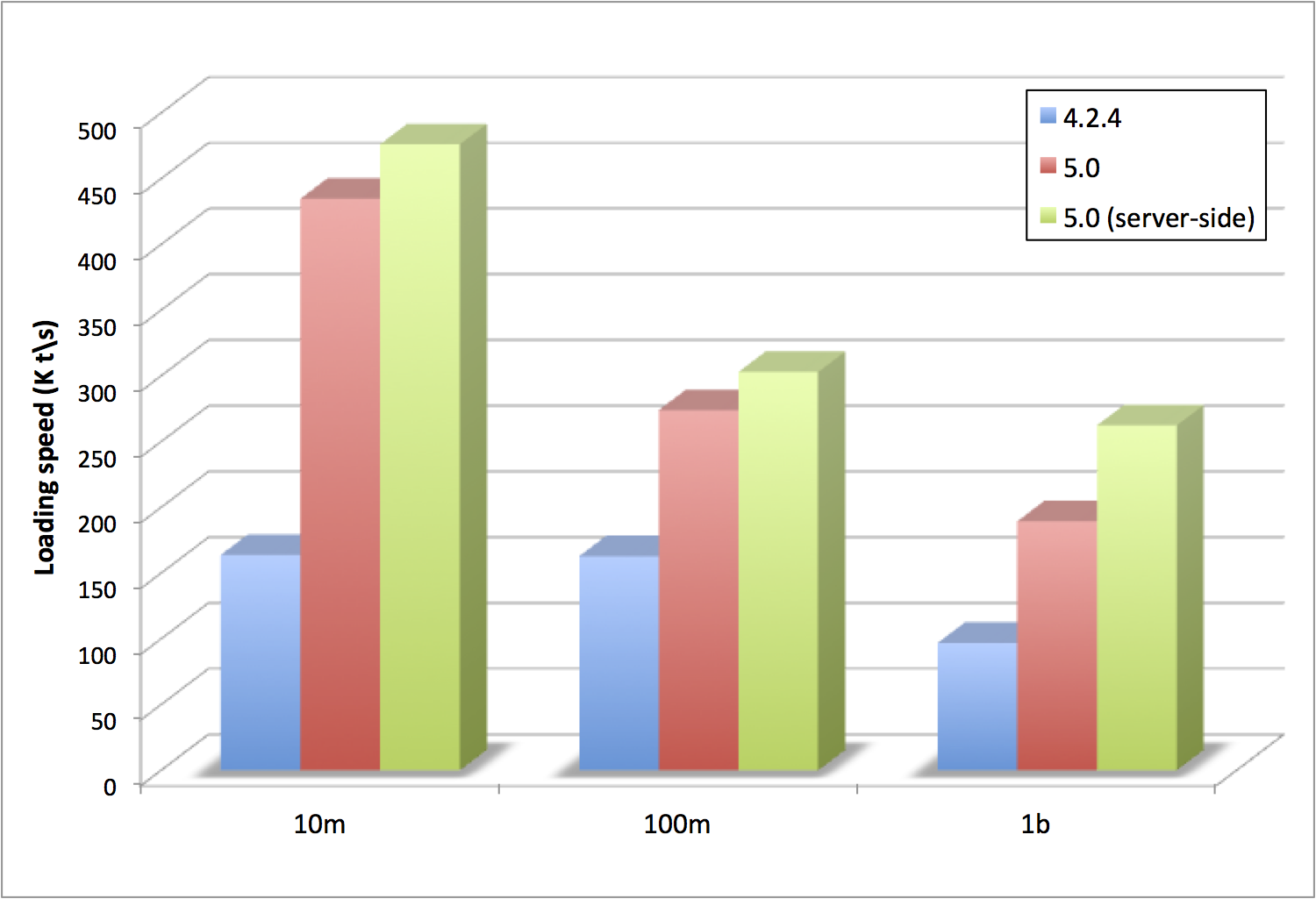
Data load speed performance: 4.2.4, 5.0, 5.0 server side
Before Stardog 5 bulk load in the cluster (db create command) first created the database in one node and then replicated the data to the other nodes in the cluster. This approach makes error-catching eager, but when there are no errors in the data it increases loading time.
We’ve changed this behavior so that the first node that receives data starts replicating the data to other nodes immediately. All nodes will bulk load the data concurrently. This change nearly doubles the bulk loading speed in the cluster. The data transfer time between the client and the server remains unchanged, but if your files are already stored on the server machines, then you can omit the --copy-server-side option and increase the loading speed even more.
9. Pivotal Cloud Foundry? Also Trivial!
Finally, the work on Stardog Graviton was so much fun that John Bresnahan thought he’d also do the same thing for the other cloud environment we love, Pivotal’s Cloud Foundry. Thanks to our good friend, Stuart Charlton, for help on this one. Stardog PCF Service Broker paves the way for Stardog on Pivotal Network as a tiled service. Watch this space for an announcement, which should be in time for Stardog 5 final release.
Conclusion
Finally, let’s look at some software engineering stats really fast:
| Release cycle | Months | +/- lines changed | Net | PRs & Issues |
|---|---|---|---|---|
| 3.0 to 4.0 | 8 | 152,231/-112,788 | 39,443 | 419 |
| 4.0 to 5.0 | 18 | 204,476/-230,341 | -25,865 | 905 |
Stardog is net negative KLOC changed over the 4.0 to 5.0 release cycle. For 5.0 final we expect another chunk of deletion, which will put us at a net growth since 3.0 release of about 10,00 lines of code.
I described 9 reasons Stardog 5 is awesome. But the truth is that there’s only one actual reason why Stardog 5 is awesome: my coworkers are an unstoppable force of software power.
Which is to say that I’m only telling you about the amazing work of other people. It’s these amazing people who did the work—Jess Balint, John Bresnahan, Adam Bretz, Mark Ellis, Scott Fines, Michael Grove, Pavel Klinov, Paul Marshall, Stephen Nowell, Pedro Oliveira, Evren Sirin, Ty Soehngen, and Alexander Toktarev.
Stardog 5 will be the fastest, most scalable Knowledge Graph platform available anywhere.
Download Stardog today to start your free 30-day evaluation.
Kendall Clark
26 April 2017
![]()
![]()
![]()
